
Disclaimer: I am sure that this post is full of mistakes, grammar and so on. Forgive me, I was - and still am - learning and discovering new things about Kubernetes.
As I mentioned in a few other posts before, I'm running gitplac.si - a self-hosted GitLab instance that is basically invite-only at the time being. I also use the domain gitpage.si for GitLab's integrated GLpages and I registered the gitapp.si domain for application hosting via instance wide Kubernetes.


Soon (tm) I will be migrating all VMs on my primary virtualization node (currently an HPE dl380 gen7) to my new gen8 which has 256GB of ram - I am always on 75-85% ram usage on the gen7, so I decided to give the new node an upgrade.
# Day one
Now, how I would go about setting everything up? I have no clue. I've never talked about, let alone used Kubernetes. It sure sounds useful with all these thingies like "ingress" for instant webserver deployment, having whole container clusters just being deployed to production with a few clicks and so on, but is it really that good? ... no clue. I guess I'll find out in the next few days.
Turns out that this will take much more time than a few days, but hey - who am I to judge.
I started with creating a VM on my desktop with a fresh GitLab-ce installation, but realized in some time that it isn't worth it, because I only have 8GB of ram in my desktop PC, so I created two new VMs on my virtualization node with Cento7 minimal installation on them.

I later updated them both, installed my preferred packages such as htop, bmon, glances, tmux, screen and vim. After that I shut them both down and created snapshots - it's so useful to have a post-update snapshot of the VMs you use for learning. Just in case you make a little fuckup. I - again - installed GitLab on the first VM, finished with some basic configuration, shut it down, created another snapshot and moved on to the second one - where the kubernetes cluster is going to be installed.
Now you need to keep in mind that I had no clue about how kubernetes works, what's the hierarchy in it's grand scheme of things, what controlls what and so on. I had no clue about anything. I was searching for tutorials about "how to install kubernetes on bare metal server", because at the start I didn't know that it just uses docker. I thought that it used some custom-made virtualization runtime or something. And so I found some tutorials, read them, moved on to some other ones and eventually I got to two recordings of seminars that were uploaded by CNCF (Cloud Native Computing Foundation) on YouTube:
- Self-Hosted Kubernetes: How and Why [I] - Diego Pontoriero, CoreOS
- KubeCeption! A Story of Self-Hosted Kubernetes by Aaron Levy, CoreOS, Inc.
I watched both of them and only now I realized that while I was searching "self hosted kubernetes" on DuckDuckGo, I wasn't actually getting results about how to run kubernetes clusters on your own server (which is what I actually wanted to know) - no, no! I was getting results about "how to host your kubernetes core services, such as the API and the scheduler, on the same kubernetes instance that they manage". I guess that if I wanted to get the results that I was actually searching for I should search for "how to host kubernetes on premises"
I also found the following in the kubernetes docs: Creating a single control-plane cluster with kubeadm. I've already heard about this kubeadm before is some other resources - I can't really recall which ones - but I still don't get what it does and what it's essentially used for, because I don't really understand everything. I don't have the whole image of how this whole thing works. So back to that doc... It's a tutorial of course, but half of the things in there are like black magic to me. So I just run through it, I run the commands, I skip some - it's a VM afterall, I can always rollback to the "postsetup" snapshot.
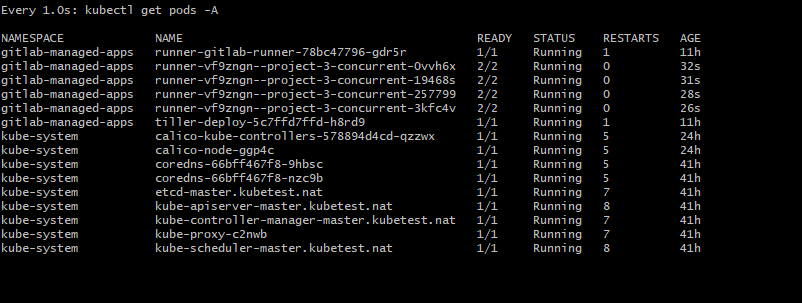
After I finish with it I run the kubectl get pods -A and lo and behold, something's listed! Without reading anything that was written in that output table I went to GitLab's kubernetes setup, I added the clusted and it worked! (on the second try - I used the wrong credentials the first time I tried). Now I just had to click one button to install Helm on the cluster and we're ready to go, right? Wrong! I clicked the "install" button and the installation of Helm started - or so I thought. I waited for five minutes, then for fifteen then I came back after about an hour and I saw an error telling me that the Helm intallation failed and that I should check the pod logs. I had no clue how to look at the logs, so I spent another fifteen minutes searching for the command and I finally found it; kubectl logs install-helm -n gitlab-managed-apps so I ran it and I got a new error;
gitlab Something went wrong while installing Helm Tiller
Operation timed out. Check pod logs for install-helm for more details.Error: error initializing: Looks like "https://kubernetes-charts.storage.googleapis.com" is not a valid chart repository or cannot be reached: Get https://kubernetes-charts.storage.googleapis.com/index.yaml: dial tcp: lookup kubernetes-charts.storage.googleapis.com on 10.96.0.10:53: server misbehaving# Day two
I'm not home - can't really work on any of this stuff.
# Day three
Alrighty, so now I've had some time to actually process everything I've got so far and I'm able to "connect the dots". I got back to work, connected to the VM and check out the pod logs - just to refresh my memory - and went on to search for tutorials or something that could help me out.
After a while I looked at the kubectl get pods -A output again and saw that some pods were in "pending" state - pending for what? This was the very first of those "eureka-wtf" moments with Kubernetes, because it worked... ...almost. So I searched for "kubernetes pod pending" and the very first hit was kubernetes' docs with title "Troubleshoot Applications" which had the "My pod stays pending" section... ...which was quite useless because I had enough resources allocated to that VM with 16vCores and 12gigs of ram and I was not using any hostPort pods.
The pods that were pending were the "coredns" pods, so after looking for a little longer I found a github issue that had a especially useful reply which was helpful to me because I remembered seeing "Calico" in the kubeadm installation doc. I skipped this, because I thought that the networking is ready-to-go in Kubernetes installations, but apparently it is not? I don't know enough yet to make any assumptions, but we're getting there... ...slowly.
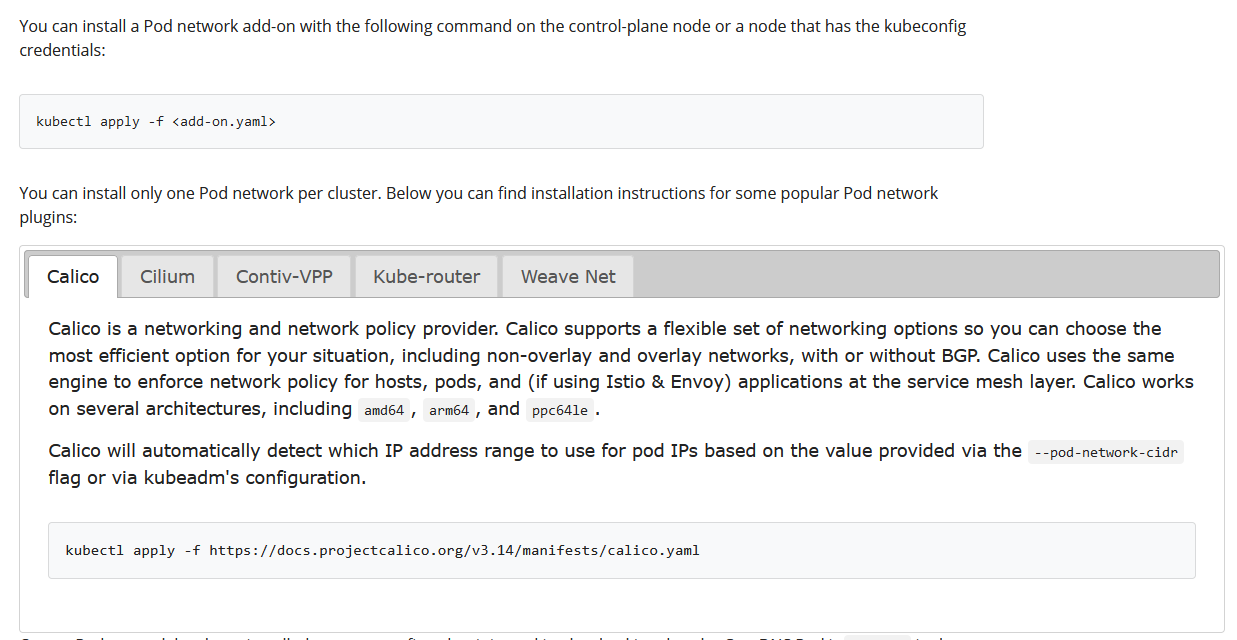
I executed the kubectl apply -f https://docs.projectcalico.org/v3.14/manifests/calico.yaml command and the coredns pods started up! I retried the Helm installation via the Gitlab administration UI, but it failed again. After searching for some time, reading issues on GitHub and other random resources I read that the node where the system core pods are hosted is "tainted" (for security reasons), so in order to run other pods on the same node, you need to untaint it (docs). After executing kubectl taint nodes --all node-role.kubernetes.io/master- on the node, the helm-installed pod start up and I finally finished the installation.
I've imported a VueJS project with a simple CI pipeline that bundles the app, manually started ~8 pipelines and it worked!
It's 5:36pm and I've tested if the cluster picks itself up after a reboot - success!
6:26pm - currently the CI runner works on the testing single-node-cluster installation. I've stress-tested the node with a long queue of CPU heavy jobs and it works good. After playing around with that I tried installing Ingress and Prometheus, but both installations fail with "INSTALL FAILED" and "Error: release prometheus failed: timed out waiting for the condition" in the pod log. After some searching I found this Impossible to install ingress with Helm tiller issue and it looks like this issue has been around for a while and it still has no reply from GitLab staff.
I'm slowly giving up on this idea of having a nice environment for developing and deploying applications and web pages.
- 6:34pm
6:42pm - I'll give this MetalLB - thing from this reply in the GitLab issue - a go. Apparently I just have to install it and give the Ingress installation another go. I shutdown the VM, created a new snapshot, started it back up and applied the new manifests.
6:48pm - MetalLB pods are running without any issues (at least I haven't noticed anything yet)
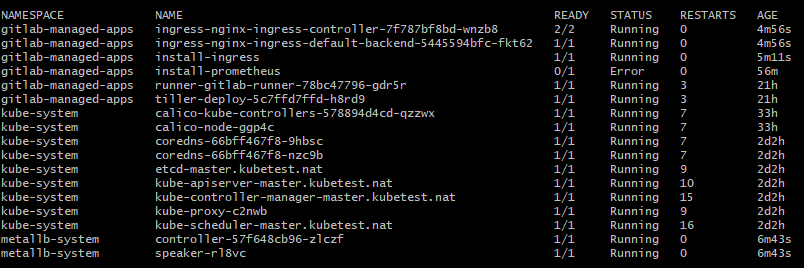
6:50pm - this changed nothing. The Ingress installation still fails.
6:52pm - I'm a dingus! I forgot to configure MetalLB... Apparently it doesn't do shit until you configure it anyway, so let's get to it.
7:19pm - After reading for a while and trying to understand what this whole thing is about, I created the file with the default layer 2 configuration, applied it and rebooted the system to test if the CI runner still works as it did before (since it was the only thing that was working just as expected) - and it did, all CI jobs finished successfully.
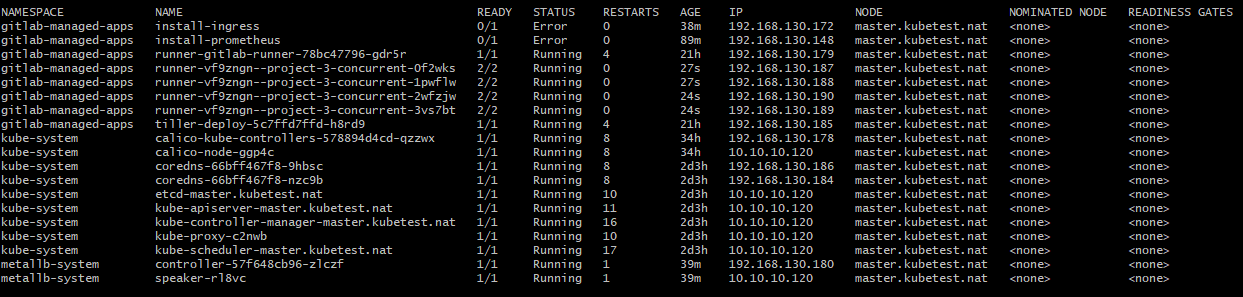
Since everything worked just as expected (up until now) I created a snapshot and started the Ingress installation - ...which failed. ...again.
# Day four and five
I allocated my time to some other projects. I was a bit sick of not getting things done - although I should be used to the feeling already it still gets to me sometimes... especially when I have too high expectations.
# After a long time...
Alright, so... ... I totally forgot about this post - so let's fill the gap that I created overtime.
After day six I got back to some other projects which ultimately lead to me totally forgetting about this plan of mine and a few weeks later I started my three week "internship" where I learned how to - this time properly - setup a k8s cluster. I was also introduced to Ansible and Helm.
It's 29th of August - school starts in four days and - if everything goes as planned - I will have my new node deployed in a few weeks, so I need to finish this thing.
And since this post is supposed to include the "learning stage" of my Kubernetes adventure, I will stop right here and publish it.
